HTML이 언어라고?
개발을 막 시작한 사람들은 이런 대화 한 번쯤 들어봤을 거에요.
🙋♀️: 너 무슨 언어 할 줄 알아?
🧑💻: 나? HTML 잘 해!
🙄: ...? 그건 언어가 아니잖아!
HTML은 이름부터 Language가 들어가는데 언어가 아니라고?
그럼 도대체 HTML은 뭐고, 왜 언어라고 하면 안 되는 걸까요?
HTML은 언어가 아니다
HTML은 HyperText Markup Language의 약자로, 프로그래밍 언어가 아니라 마크업 언어입니다.
프로그래밍 언어가 되려면 기본적으로 갖춰야 할 것들이 있어요. 예를 들어 반복문(for), 조건문(if), 변수 같은 기능들이죠.
하지만 HTML은 그런 기능이 없고, 단순히 문서의 구조와 의미를 표현하는 역할만 합니다.
그럼 HTML의 실체는 뭘까요?
HTML은 문자열이다
사실 HTML은 특별한 게 아니고, 단순히 구조를 표현하는 문자열에 불과해요. 우리가 하는 일은 이 문자열을 해석해서 의미 있는 구조를 만들고, 그것을 바탕으로 웹페이지를 만드는 것뿐이죠.
예를 들어, 우리가 만든 간단한 HTML 파일은 이렇게 생겼어요.
<html>
<body>
<h1>Hello World</h1>
</body>
</html>
이 HTML은 결국 하나의 문자열로 처리됩니다.
const htmlExample = `<html><body><h1>Hello World</h1></body></html>`;
그런데 이 단순한 문자열이 어떻게 우리가 보는 웹페이지가 되는 걸까요?
HTML이 웹페이지가 되는 과정
HTML은 파싱, Parsing을 통해서 특정 의미를 가지는 부분으로 분리되고 데이터의 구조를 가져요.
지금 작성한 간단한 HTML이 어떻게 분리되고 구조가 변하는지 살펴보면서 공부해봐요!
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>HTML Parser</title>
</head>
<body>
<h1 class="hello">
<div>Hello World</div>
<p>HTML</p>
</h1>
</body>
</html>
이 HTML은 결국 아래와 같은 트리 구조를 가지게 돼요.
html
├─ head
│ ├─ meta (charset="UTF-8")
│ ├─ meta (viewport)
│ └─ title
└─ body
└─ h1 (class="hello")
├─ div (내용: Hello World)
└─ p (내용: HTML)
이를 그림으로 나타내면 다음과 같이 볼 수 있어요.
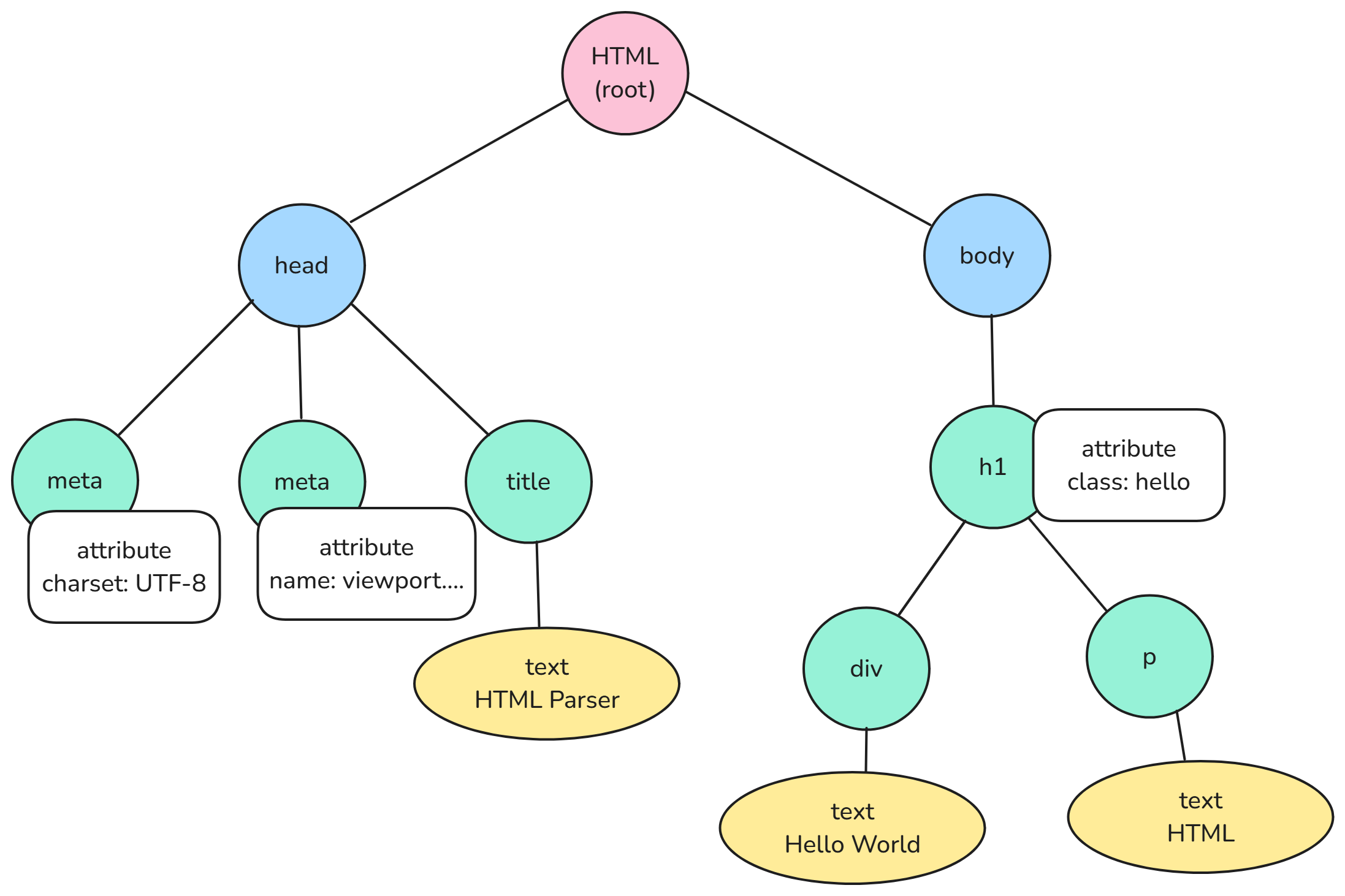
이 트리를 DOM(Document Object Model) 트리라고 부릅니다. 렌더링 엔진이 HTML 태그를 자동으로 파싱해서 이런 트리 구조를 만들어 주는 거죠.
하지만, HTML 태그만으로 만든 DOM 트리는 집으로 치면 ‘뼈대’에 불과합니다. 물론 이 상태로도 웹페이지를 만들 수 있지만, 제대로 쓰기에는 부족해요.
그래서 스타일 정보를 담은 또 다른 트리와 이를 합친 트리가 추가로 필요합니다. 이 작업도 모두 렌더링 엔진이 담당해요!
렌더링 엔진(Rendering Engine)의 동작
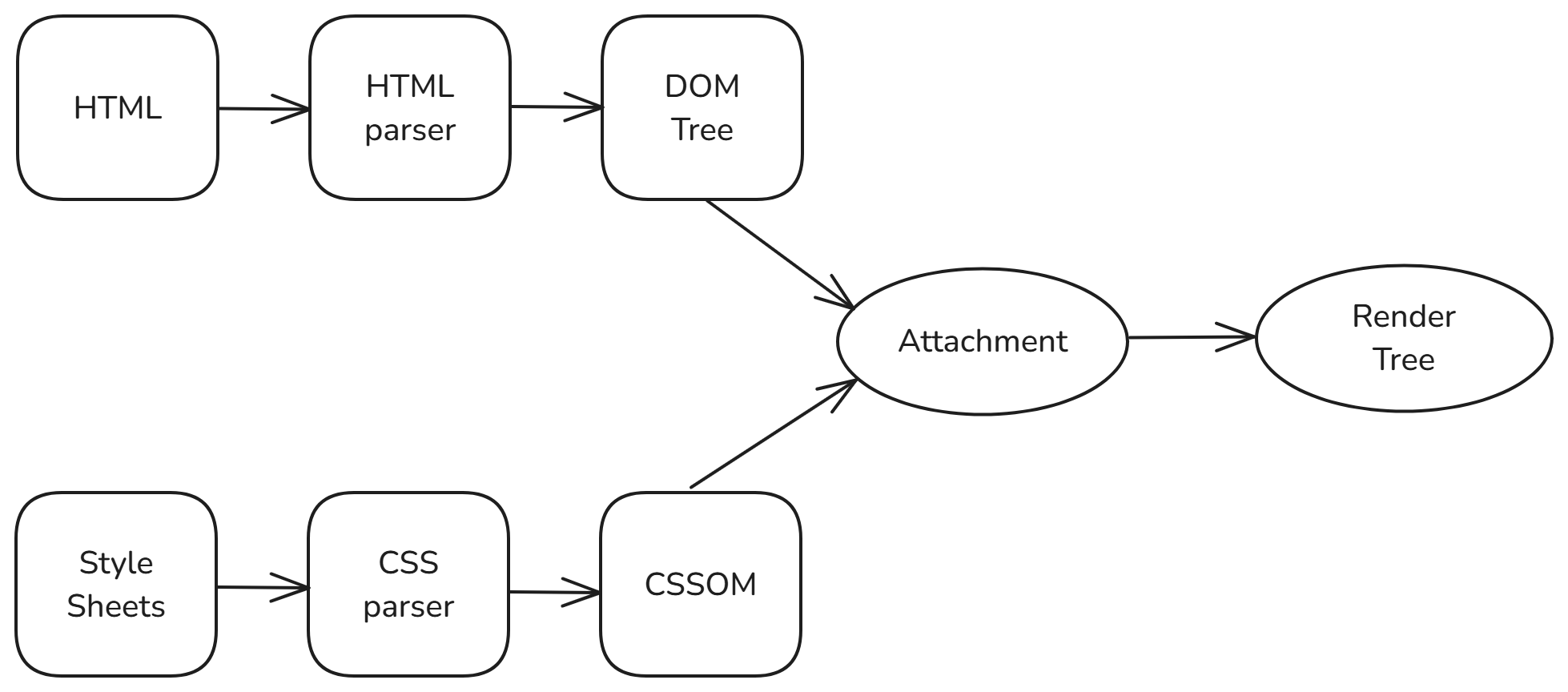
그림에서 나온 3가지 트리
- 돔 트리(DOM Tree): HTML을 파싱해서 만든 문서 구조 트리입니다. 화면에 어떤 요소들이 있는지 나타내죠.
- CSSOM: CSS를 파싱해서 만든 스타일 정보 객체입니다. 각 요소가 어떤 스타일을 갖고 있는지 담고 있어요.
- 렌더 트리(Render Tree): DOM과 CSSOM이 합쳐져서 만들어진 트리입니다. 실제로 브라우저가 화면에 그릴 요소와 스타일만 포함합니다.
그리고 실제로 웹사이트가 렌더링 엔진은 Layout -> Painting -> Composition이라는 과정을 추가로 진행해요. 이번 글에선 다루지 않을 내용이라 자세한 설명은 생략했어요.
돔 트리와 CSSOM을 만들 때는 기본적으로 문자열을 입력으로 받기 때문에, 이를 처리하는 알고리즘인 파싱이 반드시 필요합니다!
참고로, 렌더 트리는 문자열이 아닌, 돔 트리와 CSSOM을 기반으로 병합해서 만들어지는 트리예요.
그렇다면, 파싱은 무엇이고 어떻게 하는 걸까요?
파싱(Parsing)
앞서 말했듯, 파싱을 통해서 HTML을 돔 트리로 만든다는 사실을 알았습니다.
파싱은 일정한 규칙을 가진 문자열을 의미 있는 구조로 바꾸는 과정입니다.
이 과정은 크게 두 단계로 이루어집니다.
-
어휘 분석(Lexical Analysis) 문자열을 읽어 의미 있는 최소 단위인 **토큰(Token)**으로 분리하는 과정입니다. 예를 들어, 이메일 주소
example@google.com은 @나 .을 기준으로 나누어 토큰으로 분리됩니다. -
구문 분석(Syntax Analysis) 토큰들을 모아서 문법적인 구조, 즉 트리 형태로 만듭니다. 여기서 HTML 태그의 중첩 관계나 속성 등이 구조화돼요.
우리가 지금 하는 HTML 파싱을 예로 들면, 태그 같은 일정한 구조를 가진 HTML이라는 마크업 언어를, 의미 있는 트리 구조로 바꾸는 작업인 셈이죠.
HTML 파싱 구현해보기
기본적인 과정은 살펴봤으니 이제 우리는 파싱을 통해서 HTML태그를 구현해 볼 거에요!
이번 HTML 파서는 TypeScript를 사용했고 스택, Stack이라는 자료구조를 이용해서 구현했어요.
우선 HTML의 구조가 어떻게 생겼는지 정의된 interface부터 보고 이야기를 시작할게요.
HTML Interface
interface HTMLNode {
type: "element" | "text";
tagName?: string;
attributes?: Record<string, string>;
children: HTMLNode[];
content?: string;
}
우리가 이용할 HTMLNode의 interface는 위와 같이 생겼어요! 처음엔 어려울 수 있으니 각각의 요소에 대해서 간단하게 설명할게요.
-type: 노드가 텍스트인지, 아니면 요소(element)인지 구분해줘요. "element"면 텍스트가 아닌 HTML 태그를 뜻해요.
-tagName: HTML 태그의 이름이에요. 예를 들어 div, p, button 같은 거죠.
-attributes: 태그에 들어가는 속성들을 담아요. 예를 들면 class, id, onclick 같은 것들이 여기에 포함돼요.
-children: 가장 중요한 자식 노드들을 담는 배열이에요. HTML 요소 안에 포함된 하위 태그들이나 텍스트가 들어가요.
-content: 텍스트 노드에 실제 들어가는 글자 내용을 저장해요.
children 에 대한 예시를 들자면 다음 HTML 에서
<div>
<p>Children</p>
<button>Click</button>
</div>
div의 children 배열에는 <p>Children</p>와 <button>Click</button> 두 개의 노드가 들어가게 됩니다.
이제 본격적으로 HTML 파서를 구현해볼게요.
HTML 파서 구현하기
전체적인 순서만 잡는다면, 어렵지 않게 이해하실 수 있을거라 생각해요.
우선 큰 흐름은 다음과 같아요.
- 여는 태그(<)가 나왔는지 확인하기
<div>인지</div>인지 구분하기</처럼 닫는 태그일 경우, 스택에서 pop<div>처럼 여는 태그라면<img/>같은 self-closing이 아니면 새로운 노드를 push- 텍스트인 경우, 텍스트 노드를 생성
위 단계를 따라 코드를 구현할거에요. 그 전에, 기본적으로 확인할 요소들을 먼저 확인할게요.
Root Element 생성
HTML 파싱은 트리 구조를 만드는 작업이기 때문에, 그 기반이 되는 루트 노드부터 만들어야 해요.
const rootNode: HTMLNode = {
type: "element",
tagName: "root",
children: [],
};
root라는 이름의 최상위 노드를 하나 만들어줍니다. 이 노드 아래로 우리가 파싱할 모든 HTML 요소들이 트리 형태로 붙게 돼요. 이게 바로 DOM 트리의 시작점이 되는 거죠.
기본 변수 정의
그다음엔 파싱에 필요한 기본 변수들을 정의해줘야겠죠.
let currentPosition = 0;
const stack: HTMLNode[] = [rootNode];
여기서 stack은 노드 간의 계층 구조를 관리하기 위한 자료구조예요. 여는 태그가 나오면 새로운 노드를 만들고 스택에 push, 닫는 태그가 나오면 현재 노드를 pop하는 식으로요.
스택은 가장 나중에 들어온 게 가장 먼저 나가는 (LIFO) 구조이기 때문에 HTML 처럼 중첩된 구조를 파싱할 때 딱 맞는 도구예요.
🔗 혹시 스택에 대해 더 알고 싶다면 스택 연산 (BOJ 10828) 문제를 참고해 보세요. 스택의 기본 연산이 잘 정리되어 있답니다.
또한, currentPosition은 현재 HTML 문자열에서 파싱하고 있는 위치를 나타내요. 우리가 문자열을 순서대로 읽어가면서 태그를 찾아야 하기 때문에 이 변수가 필요하답니다.
이제 정말 본격적으로 구현을 살펴볼게요.
1️⃣, 2️⃣, 3️⃣ 기본적인 함수의 구조와 태그 처리 (<, 닫는 태그)
함수는 다음과 같은 구조를 따르는 것을 알 수 있습니다.
기본적인 함수 구조
// Interface 정의
// HTML 을 파싱하는 함수
export default function parseHtml(htmlString: string): HTMLNode {
// 변수 정의
while (currentPosition < htmlString.length) {
// 1️⃣ < 가 오는 경우
if (htmlString[currentPosition] === "<")
// 2~5 에 해당하는 각각 케이스를 구현하기
}
// 최종적으로 파싱된 트리 return
return rootNode;
}
기본적으로 반복문을 통해 currentPosition을 이동시키며 모든 요소를 파싱해요.
<이 시작점 역할을 하기 때문에 기준으로 잡아요.
여러 경우가 있지만 큰 로직은 다음과 같이 볼 수 있어요.
주석 처리
if (htmlString.startsWith("<!--", currentPosition)) {
const commentEnd = htmlString.indexOf("-->", currentPosition);
if (commentEnd !== -1) {
currentPosition = commentEnd + 3;
} else {
currentPosition = htmlString.length;
}
}
주석의 경우 DOM 트리에 들어가지 않기 때문에 스킵하고 넘어가요.
닫는 태그인 경우
if (htmlString[currentPosition + 1] === "/") {
const endTagStart = currentPosition;
currentPosition = htmlString.indexOf(">", currentPosition) + 1;
// 루트 노드를 제외한 나머지 요소 pop
if (stack.length > 1) {
stack.pop();
}
}
</인 경우, 즉 닫는 태그인 경우를 뜻해요. 이 경우에는 태그가 끝나기 때문에 남은 요소들을 pop 해서 지워주면 됩니다.
4️⃣ 여는 태그(>) 이거나 self-closing(<img/>) 인 경우
이 파트는 DOM 트리의 새로운 노드를 생성하는 핵심 로직이에요. 여는 태그(<div>, <span> 등)와 self-closing 태그(<img />, <br /> 등)를 구분해서 파싱합니다.
이번 코드의 핵심 로직인 만큼, 차근차근 하나씩 구현해볼게요.
1. 태그의 시작과 끝 찾기
const tagStart = currentPosition;
let tagEnd = htmlString.indexOf(">", currentPosition);
if (tagEnd === -1) {
tagEnd = htmlString.length;
}
현재 위치에서 가장 가까운 >을 찾고 >가 없는 경우에는 에러 처리를 합니다.
2. 태그 이름 추출
const tagContent = htmlString.substring(tagStart + 1, tagEnd);
const spaceIndex = tagContent.indexOf(" ");
const tagName =
spaceIndex !== -1 ? tagContent.substring(0, spaceIndex) : tagContent;
공백을 기준으로 태그 이름만 추출합니다.
3. self-closing 태그 여부 확인
const selfClosing = tagContent.endsWith("/");
<img/>등을 처리합니다.
4. 새 HTMLNode 객체 생성
const newNode: HTMLNode = {
type: "element",
tagName: tagName.toLowerCase(),
attributes: {},
children: [],
};
트리를 만들기 위한 새 노드를 생성합니다.
5. Attribute 파싱
if (spaceIndex !== -1) {
const attrString = tagContent.substring(spaceIndex + 1);
const attrMatches = attrString.match(/(\w+)\s*=\s*"([^"]*)"/g);
if (attrMatches) {
attrMatches.forEach((attr) => {
const [name, value] = attr.split("=").map((s) => s.trim());
if (newNode.attributes) {
newNode.attributes[name] = value.replace(/"/g, "");
}
});
}
}
정규식을 활용하여 속성을 찾고, 속성 이름과 값을 잘라서 attributes 객체에 저장합니다.
6. 현재 열린 태그의 자식으로 추가
stack[stack.length - 1].children.push(newNode);
스택에 새로 만든 newNode를 부모의 children에 넣어줍니다.
7. self-closing 이 아니면 스택에 push
if (!selfClosing) {
stack.push(newNode);
}
닫는 태그가 나온다면 스택에 push 합니다.
8. 커서 이동
currentPosition = tagEnd + 1;
다음 파싱을 위한 준비를 합니다.
5️⃣ 텍스트 노드 처리
순수한 문자열(텍스트)만 처리하는 부분입니다. 이 부분에서는 태그가 아닌 텍스트 콘텐츠만 추출해서 text 타입의 노드를 만들어 DOM 트리에 추가해요.
1. 텍스트의 시작과 끝 찾기
const textStart = currentPosition;
let textEnd = htmlString.indexOf("<", currentPosition);
if (textEnd === -1) {
textEnd = htmlString.length;
}
<를 만나기 전까지 텍스트가 나와야 하므로 읽고 예외처리를 합니다.
2. 텍스트의 추출 및 공백 제거
const text = htmlString.substring(textStart, textEnd).trim();
substring()과 trim()을 이용하여 공백 없는 문자열을 얻습니다.
3. 텍스트 노드 생성 후 트리 추가
if (text) {
const textNode: HTMLNode = {
type: "text",
content: text,
children: [],
};
stack[stack.length - 1].children.push(textNode);
}
text가 있는 경우 텍스트 노드를 생성합니다.
텍스트 노드의 경우 children은 없고, 이를 스택에 추가해요.
4. 커서 이동
currentPosition = textEnd;
다음 파싱을 위한 준비를 합니다.
위 모든 과정들을 완료하면 HTML 태그를 파싱한 DOM 트리를 얻을 수 있어요.
전체 코드를 보면 다음과 같이 쓸 수 있어요.
export interface HTMLNode {
type: "element" | "text";
tagName?: string;
attributes?: Record<string, string>;
children: HTMLNode[]; // 자식 노드들의 배열
content?: string;
}
export default function parseHtml(htmlString: string): HTMLNode {
// 루트 노드 생성
const rootNode: HTMLNode = {
type: "element",
tagName: "root",
children: [],
};
let currentPosition = 0;
const stack: HTMLNode[] = [rootNode]; // 스택을 활용하여 노드의 계층 구조를 관리
while (currentPosition < htmlString.length) {
if (htmlString[currentPosition] === "<") {
// 주석 처리
if (htmlString.startsWith("<!--", currentPosition)) {
const commentEnd = htmlString.indexOf("-->", currentPosition);
if (commentEnd !== -1) {
currentPosition = commentEnd + 3;
} else {
currentPosition = htmlString.length;
}
} else if (htmlString[currentPosition + 1] === "/") {
const endTagStart = currentPosition;
currentPosition = htmlString.indexOf(">", currentPosition) + 1;
// 루트 노드를 제외한 나머지 요소 pop
if (stack.length > 1) {
stack.pop();
}
} else {
const tagStart = currentPosition;
let tagEnd = htmlString.indexOf(">", currentPosition);
if (tagEnd === -1) {
tagEnd = htmlString.length;
}
const tagContent = htmlString.substring(tagStart + 1, tagEnd);
const spaceIndex = tagContent.indexOf(" ");
const tagName =
spaceIndex !== -1 ? tagContent.substring(0, spaceIndex) : tagContent;
// 자체 닫는 태그인지 확인 <img /> 등
const selfClosing = tagContent.endsWith("/");
const newNode: HTMLNode = {
type: "element",
tagName: tagName.toLowerCase(),
attributes: {},
children: [],
};
// 속성 추출
if (spaceIndex !== -1) {
const attrString = tagContent.substring(spaceIndex + 1);
const attrMatches = attrString.match(/(\w+)\s*=\s*"([^"]*)"/g);
if (attrMatches) {
attrMatches.forEach((attr) => {
const [name, value] = attr.split("=").map((s) => s.trim());
if (newNode.attributes) {
newNode.attributes[name] = value.replace(/"/g, "");
}
});
}
}
stack[stack.length - 1].children.push(newNode);
if (!selfClosing) {
stack.push(newNode);
}
currentPosition = tagEnd + 1;
}
} else {
const textStart = currentPosition;
let textEnd = htmlString.indexOf("<", currentPosition);
if (textEnd === -1) {
textEnd = htmlString.length;
}
const text = htmlString.substring(textStart, textEnd).trim();
if (text) {
const textNode: HTMLNode = {
type: "text",
content: text,
children: [],
};
stack[stack.length - 1].children.push(textNode);
}
currentPosition = textEnd;
}
}
return rootNode;
}
그리고 이 전체 코드를 이용해서 밑 코드를 실행하면 출력 결과는 다음과 같아요.
HTML 이 있는 index.ts
import parseHtml, { HTMLNode } from "./parseHtml.js";
const htmlString = `
<html>
<head>
<title>Hello</title>
</head>
<body>
<div class="hello">Hello</div>
<div class="world">World</div>
<div class="button">
<button>Click me</button>
<p><img src="*" alt="image" />Image</p>
<span id="span">Hello World</span>
</div>
</body>
</html>`;
const parsedHtmlResult: HTMLNode = parseHtml(htmlString);
console.log(JSON.stringify(parsedHtmlResult, null, 2));
출력 결과
{
"type": "element",
"tagName": "root",
"children": [
{
"type": "element",
"tagName": "html",
"attributes": {},
"children": [
{
"type": "element",
"tagName": "head",
"attributes": {},
"children": [
{
"type": "element",
"tagName": "title",
"attributes": {},
"children": [
{
"type": "text",
"content": "Hello",
"children": []
}
]
}
]
},
{
"type": "element",
"tagName": "body",
"attributes": {},
"children": [
{
"type": "element",
"tagName": "div",
"attributes": {
"class": "hello"
},
"children": [
{
"type": "text",
"content": "Hello",
"children": []
}
]
},
{
"type": "element",
"tagName": "div",
"attributes": {
"class": "world"
},
"children": [
{
"type": "text",
"content": "World",
"children": []
}
]
},
{
"type": "element",
"tagName": "div",
"attributes": {
"class": "button"
},
"children": [
{
"type": "element",
"tagName": "button",
"attributes": {},
"children": [
{
"type": "text",
"content": "Click me",
"children": []
}
]
},
{
"type": "element",
"tagName": "p",
"attributes": {},
"children": [
{
"type": "element",
"tagName": "img",
"attributes": {
"src": "*",
"alt": "image"
},
"children": []
},
{
"type": "text",
"content": "Image",
"children": []
}
]
},
{
"type": "element",
"tagName": "span",
"attributes": {
"id": "span"
},
"children": [
{
"type": "text",
"content": "Hello World",
"children": []
}
]
}
]
}
]
}
]
}
]
}
위와 같이 DOM 트리가 잘 나오는 것을 알 수 있어요.
다음 글로는 CSSOM 을 파싱을 구현하고 이를 설명하는 글을 작성할게요.
전체 코드는 제 깃허브에서도 확인할 수 있어요.
댓글이나 피드백은 언제나 환영입니다.😊